Predicting DNA Sequence Similarity Across Species Using Machine Learning: a K-mer Based Approach
DOI:
https://doi.org/10.22452/Keywords:
DNA classification, machine learning, K-mer, naive bayesAbstract
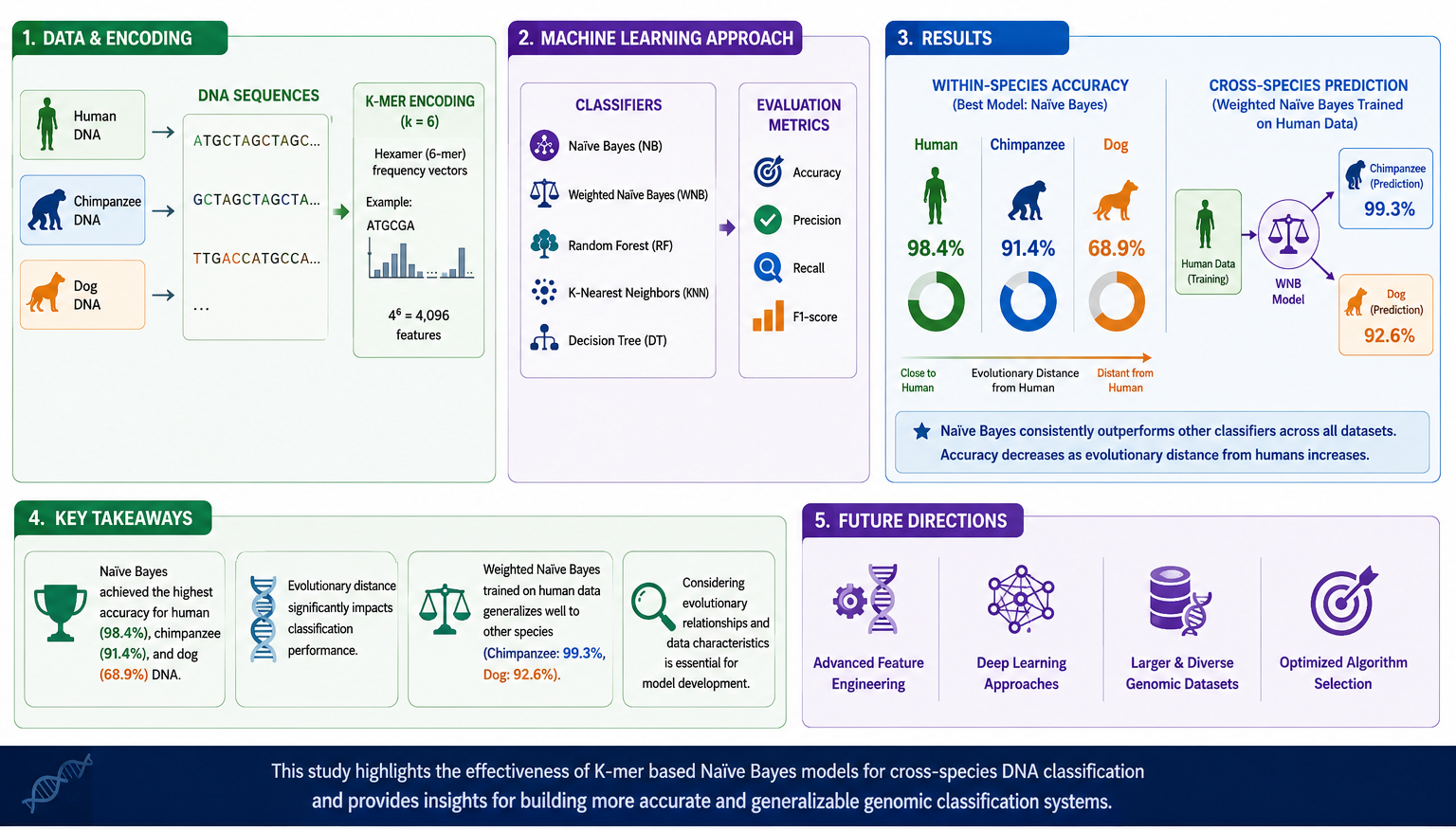
This study examines the effectiveness of machine learning methods for categorizing DNA sequences across human, chimpanzee, and dog samples. We employed k-mer encoding to renovate DNA structures into numerical representations suitable for machine learning models. Four classifiers, such as naive bayes and weighted naive bayes, random forest, K-nearest neighbors, and decision tree, were applied and evaluated using accuracy, precision, recall, and F1-score. The naive bayes classifier consistently outperformed the others across all three datasets, achieving the highest accuracy in classifying human DNA (98.4%), followed by chimpanzee DNA (91.4%), and exhibiting significantly lower accuracy for dog DNA (68.9%). This performance disparity is attributed to the increasing evolutionary distance from human DNA. Additionally, a weighted naive bayes model that was trained on human data showed very high accuracy in predicting chimpanzee (99.3%) and dog (92.6%) DNA sequences. The results presented here show the significance of taking into account evolutionary relations and dataset features whenever developing and training classification models for genetic sequence analysis. The research extends the present research by evaluating the performance of several different algorithms on separate DNA databases, identifying strengths and weaknesses, and suggesting avenues for future research focusing on advanced feature engineering and algorithm selection for improved cross-species classification.
References
Momenzadeh, M., Sehhati, M., & Rabbani, H. (2020). Using hidden Markov model to predict recurrence of breast cancer based on sequential patterns in gene expression profiles. Journal of Biomedical Informatics, 111, 103570.
Nayak, J., Mishra, M., Naik, B., Swapnarekha, H., Cengiz, K., & Shanmuganathan, V. (2022). An impact study of COVID‐19 on six different industries: Automobile, energy and power, agriculture, education, travel and tourism and consumer electronics. Expert systems, 39(3), e12677.
Benson, D. A., Karsch-Mizrachi, I., Lipman, D. J., Ostell, J., & Sayers, E. W. (2009). GenBank. Nucleic acids research, 37(suppl_1), D26-D31.
Solis-Reyes, S., Avino, M., Poon, A., & Kari, L. (2018). An open-source k-mer based machine learning tool for fast and accurate subtyping of HIV-1 genomes. PloS one, 13(11), e0206409.
Shadab, S., Khan, M. T. A., Neezi, N. A., Adilina, S., & Shatabda, S. (2020). DeepDBP: deep neural networks for identification of DNA-binding proteins. Informatics in Medicine Unlocked, 19, 100318.
Onesime, M., Yang, Z., & Dai, Q. (2021). Genomic Island Prediction via Chi‐Square Test and Random Forest Algorithm. Computational and Mathematical Methods in Medicine, 2021(1), 9969751.
Alotaibi, H., Alsolami, F., & Mehmood, R. (2021). DNA profiling: An investigation of six machine learning algorithms for estimating the number of contributors in DNA mixtures. International Journal of Advanced Computer Science and Applications, 12(11).
Arowolo, M. O., Adebiyi, M. O., & Adebiyi, A. A. (2021). A genetic algorithm approach for predicting ribonucleic acid sequencing data classification using KNN and decision tree. TELKOMNIKA (Telecommunication Computing Electronics and Control), 19(1), 310-316.
Mathur, G., Pandey, A., & Goyal, S. (2023). A comprehensive tool for rapid and accurate prediction of disease using DNA sequence classifier. Journal of Ambient Intelligence and Humanized Computing, 14(10), 13869-13885.
Arowolo, M. O., Adebiyi, M., Adebiyi, A. A., & OKesola, J. O. (2021). Predicting RNA-Seq data using genetic algorithm and ensemble classification algorithms. Indonesian Journal of Electrical Engineering and Computer Science, 21(2), 1073-1081.
Hamed, B. A., Ibrahim, O. A. S., & Abd El-Hafeez, T. (2023). Optimizing classification efficiency with machine learning techniques for pattern matching. Journal of Big Data, 10(1), 124.
Peretz, O., Koren, M., & Koren, O. (2024). Naive Bayes classifier–An ensemble procedure for recall and precision enrichment. Engineering Applications of Artificial Intelligence, 136, 108972.
Zuhanda, M. K., Permata, L., & Ongko, E. (2025). Impact of Adaptive Synthetic on Naïve Bayes Accuracy in Imbalanced Anemia Detection Datasets. Jurnal RESTI (Rekayasa Sistem dan Teknologi Informasi), 9(1), 85-93.
Xia, X., & Yan, J. (2021). Construction of music teaching evaluation model based on weighted naïve bayes. Scientific Programming, 2021(1), 7196197.
Ye, Y. (2024, May). Design and Implementation of an English Mobile Learning System Based on Weighted Naive Bayes. In 2024 5th International Conference on Big Data and Informatization Education (ICBDIE 2024) (pp. 187-196). Atlantis Press.
Pazhanikumar, K., & KuzhalVoiMozhi, S. N. (2024). Remote sensing image classification using modified random forest with empirical loss function through crowd-sourced data. Multimedia Tools and Applications, 83(18), 53899-53921.
Coscia, A., Dentamaro, V., Galantucci, S., Maci, A., & Pirlo, G. (2024). Automatic decision tree-based NIDPS ruleset generation for DoS/DDoS attacks. Journal of Information Security and Applications, 82, 103736.
Corso, M. P., Perez, F. L., Stefenon, S. F., Yow, K. C., García Ovejero, R., & Leithardt, V. R. Q. (2021). Classification of contaminated insulators using k-nearest neighbors based on computer vision. Computers, 10(9), 112.
Bhushan Bawankar. (2024). Analysis of machine learning approaches for dna sequencing and classification: An optimized approach. Communications on Applied Nonlinear Analysis, 31(2s), 436–453. https://doi.org/10.52783/cana.v31.659.
Rrmoku, K., Selimi, B., & Ahmedi, L. (2022). Application of trust in recommender systems—utilizing naive Bayes classifier. Computation, 10(1), 6.
Jackins, V., Vimal, S., Kaliappan, M., & Lee, M. Y. (2021). AI-based smart prediction of clinical disease using random forest classifier and Naive Bayes. The Journal of Supercomputing, 77(5), 5198-5219.
Wickramasinghe, I., & Kalutarage, H. (2021). Naive Bayes: applications, variations and vulnerabilities: a review of literature with code snippets for implementation. Soft Computing, 25(3), 2277-2293.
Wang, A. X., Chukova, S. S., & Nguyen, B. P. (2023). Ensemble k-nearest neighbors based on centroid displacement. Information Sciences, 629, 313-323.
Gao, L., Li, D., Liu, X., & Liu, G. (2022). Enhanced chiller faults detection and isolation method based on independent component analysis and k-nearest neighbors classifier. Building and Environment, 216, 109010.
Beskopylny, A. N., Stel’makh, S. A., Shcherban’, E. M., Mailyan, L. R., Meskhi, B., Razveeva, I., & Beskopylny, N. (2022). Concrete strength prediction using machine learning methods CatBoost, k-nearest neighbors, support vector regression. Applied Sciences, 12(21), 10864.
Downloads
Published
Issue
Section
License
Copyright (c) 2026 Malaysian Journal of Science (MJS)

This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License.
Transfer of Copyrights
- In the event of publication of the manuscript entitled [INSERT MANUSCRIPT TITLE AND REF NO.] in the Malaysian Journal of Science, I hereby transfer copyrights of the manuscript title, abstract and contents to the Malaysian Journal of Science and the Faculty of Science, University of Malaya (as the publisher) for the full legal term of copyright and any renewals thereof throughout the world in any format, and any media for communication.
Conditions of Publication
- I hereby state that this manuscript to be published is an original work, unpublished in any form prior and I have obtained the necessary permission for the reproduction (or am the owner) of any images, illustrations, tables, charts, figures, maps, photographs and other visual materials of whom the copyrights is owned by a third party.
- This manuscript contains no statements that are contradictory to the relevant local and international laws or that infringes on the rights of others.
- I agree to indemnify the Malaysian Journal of Science and the Faculty of Science, University of Malaya (as the publisher) in the event of any claims that arise in regards to the above conditions and assume full liability on the published manuscript.
Reviewer’s Responsibilities
- Reviewers must treat the manuscripts received for reviewing process as confidential. It must not be shown or discussed with others without the authorization from the editor of MJS.
- Reviewers assigned must not have conflicts of interest with respect to the original work, the authors of the article or the research funding.
- Reviewers should judge or evaluate the manuscripts objective as possible. The feedback from the reviewers should be express clearly with supporting arguments.
- If the assigned reviewer considers themselves not able to complete the review of the manuscript, they must communicate with the editor, so that the manuscript could be sent to another suitable reviewer.
Copyright: Rights of the Author(s)
- Effective 2007, it will become the policy of the Malaysian Journal of Science (published by the Faculty of Science, University of Malaya) to obtain copyrights of all manuscripts published. This is to facilitate:
- Protection against copyright infringement of the manuscript through copyright breaches or piracy.
- Timely handling of reproduction requests from authorized third parties that are addressed directly to the Faculty of Science, University of Malaya.
- As the author, you may publish the fore-mentioned manuscript, whole or any part thereof, provided acknowledgement regarding copyright notice and reference to first publication in the Malaysian Journal of Science and Faculty of Science, University of Malaya (as the publishers) are given. You may produce copies of your manuscript, whole or any part thereof, for teaching purposes or to be provided, on individual basis, to fellow researchers.
- You may include the fore-mentioned manuscript, whole or any part thereof, electronically on a secure network at your affiliated institution, provided acknowledgement regarding copyright notice and reference to first publication in the Malaysian Journal of Science and Faculty of Science, University of Malaya (as the publishers) are given.
- You may include the fore-mentioned manuscript, whole or any part thereof, on the World Wide Web, provided acknowledgement regarding copyright notice and reference to first publication in the Malaysian Journal of Science and Faculty of Science, University of Malaya (as the publishers) are given.
- In the event that your manuscript, whole or any part thereof, has been requested to be reproduced, for any purpose or in any form approved by the Malaysian Journal of Science and Faculty of Science, University of Malaya (as the publishers), you will be informed. It is requested that any changes to your contact details (especially e-mail addresses) are made known.
Copyright: Role and responsibility of the Author(s)
- In the event of the manuscript to be published in the Malaysian Journal of Science contains materials copyrighted to others prior, it is the responsibility of current author(s) to obtain written permission from the copyright owner or owners.
- This written permission should be submitted with the proof-copy of the manuscript to be published in the Malaysian Journal of Science
Licensing Policy
Malaysian Journal of Science is an open-access journal that follows the Creative Commons Attribution-Non-commercial 4.0 International License (CC BY-NC 4.0)
CC BY – NC 4.0: Under this licence, the reusers to distribute, remix, alter, and build upon the content in any media or format for non-commercial purposes only, as long as proper acknowledgement is given to the authors of the original work. Please take the time to read the whole licence agreement (https://creativecommons.org/licenses/by-nc/4.0/legalcode ).


